Real Time Video Analysis in Python Part 1 (Problem intro)
Beyond “OpenCV and Flask” for Video Analysis in Python
Introduction
Its very common that people want to do some video analysis in python. The most common way to do this is to use OpenCV and Flask. This is a great way to get started, but it has some limitations. In this series we will go beyond the basics and show you how to build a more robust and modular system. We will also talk about the limitations that Pyhton brings to the table and how to overcome them.
First Things First (OpenCV and Flask)
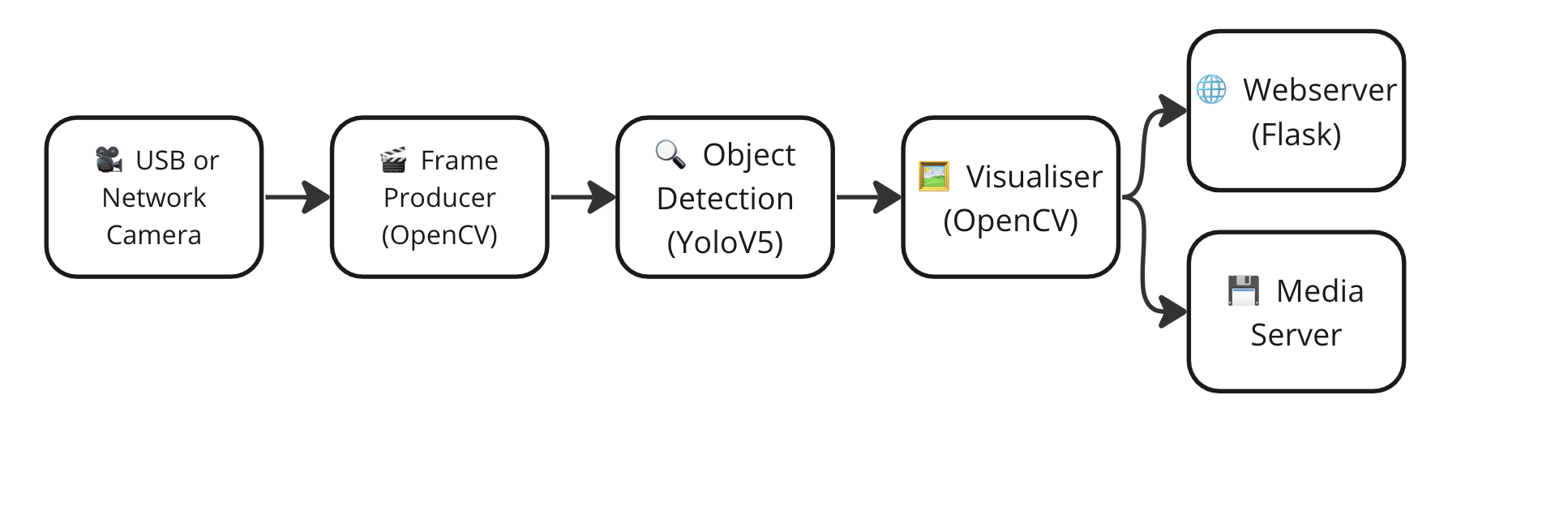
Lets go through an example of how to do video analysis in python using OpenCV and Flask. This will give us a starting point to build on. In this example we’ll use a Yolo Object Detection model and use it to detect objects in a video stream. We’ll also use a pre-trained Object detection model to detect objects in the video stream. We’ll use OpenCV to do the video capture and processing and Flask to serve the video stream to a web browser. We’ll also use Flask to serve a web page that will display the video stream and the results of the object and face detection.
Here is a component diagram of the system we are going to build:
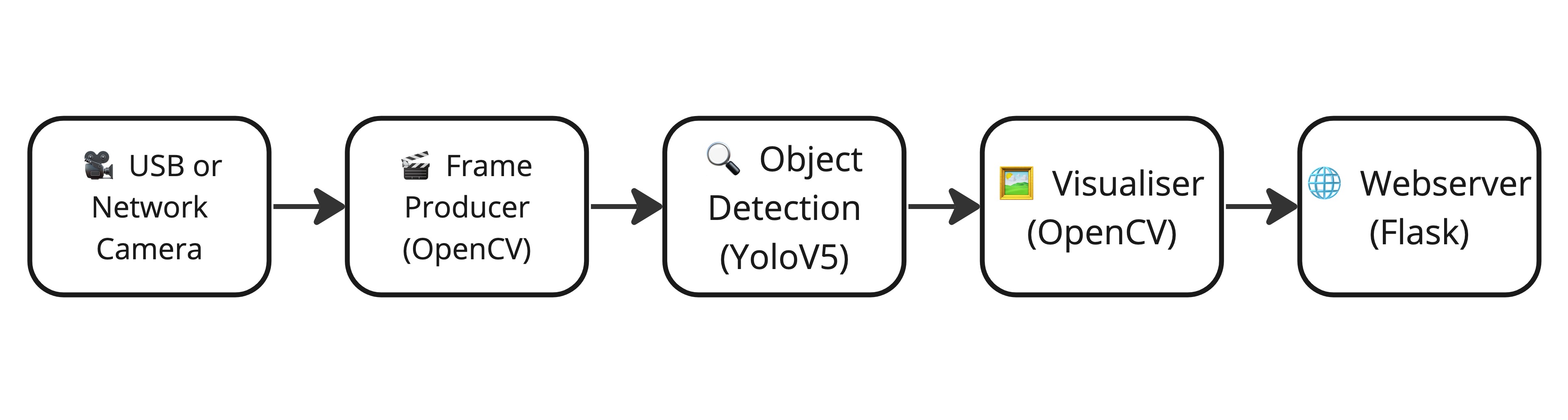
This is how the code could potentially look lile:
import cv2
from flask import Flask, render_template, Response
from detection import detect_image
app = Flask(__name__)
camera = cv2.VideoCapture(0)
def detect_objects():
while True:
success, frame = camera.read()
if not success:
break
# Perform object detection using YOLOv5
detections = detect_image(frame)
# Draw bounding boxes and labels on the frame
for class_name, confidence, bbox in detections:
x, y, w, h = bbox
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(frame, f'{class_name} {confidence:.2f}', (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# Convert the frame to JPEG format
ret, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n')
# Flask routes
@app.route('/')
def index():
return render_template('index.html')
@app.route('/video_feed')
def video_feed():
# Pay attention to mimetype here
return Response(detect_objects(), mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(debug=True)
And your index.html file:
<!DOCTYPE html>
<html>
<head>
<title>Object Detection</title>
</head>
<body>
<h1>Real-Time Object Detection</h1>
<img src="/video_feed" width="640" height="480">
</body>
</html>
The detection.py file:
import yolov5
def detect_image(image):
model = yolov5.load('yolov5s.pt')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
results = model(image)
detections = results.pred[0]
# Process and return detections
results = []
for detection in detections:
if detection is not None:
for x1, y1, x2, y2, conf, class_id in detection:
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
class_name = names[int(class_id)]
confidence = float(conf)
bbox = (x1, y1, x2 - x1, y2 - y1)
results.append((class_name, confidence, bbox))
return results
and requirements.txt file:
flask
torch
yolov5
What’s Wrong With This?
There is nothing particularly wrong with this approach. Its a simple script that works perfectly if you want to build a proof of concept and learn about video analysis in python. However, if you want to build a more robust system, you’ll need to make some changes. Here are some of the challenges you’ll face if you want to build a more robust system:
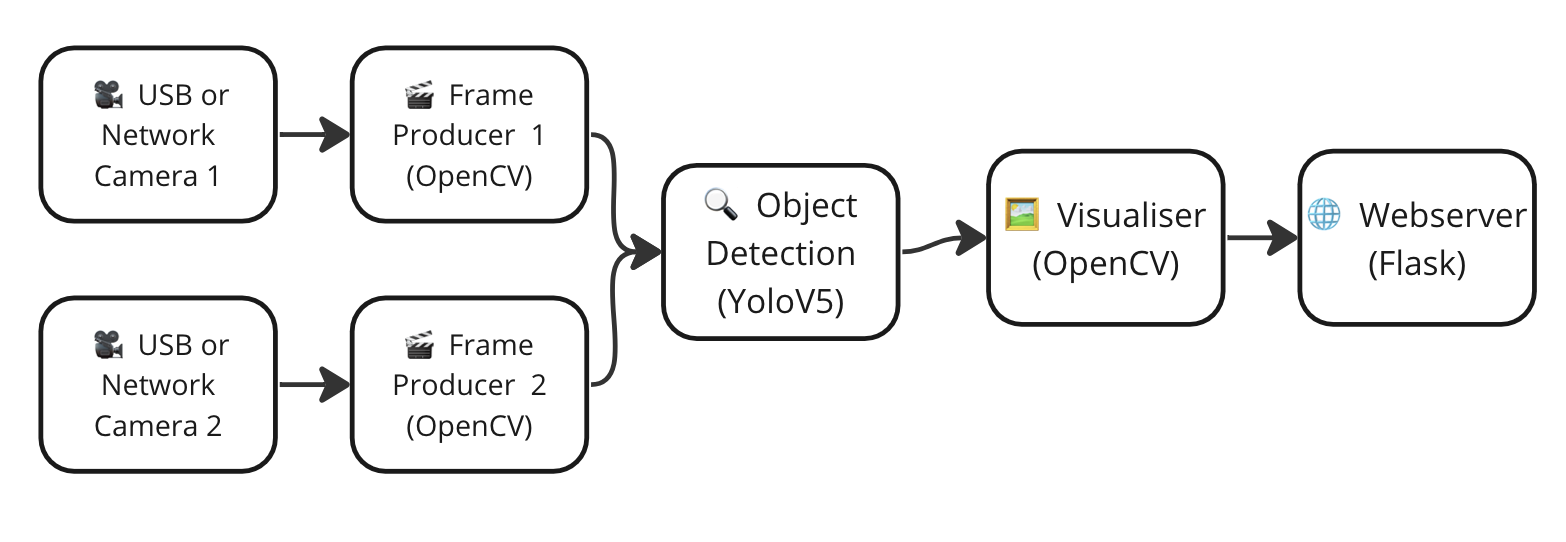
- If you need to be able to handle multiple video streams. This approach is not possible unless you process the frames sequentially.
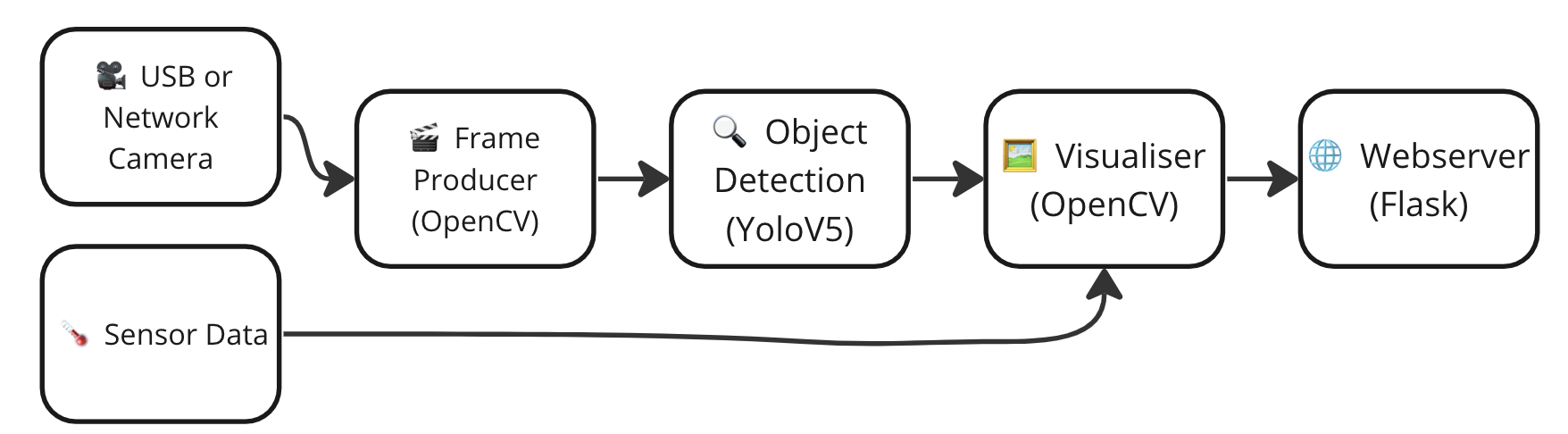
- If you have multiple sources of data like some additional metadata given by a sensor, and you want to combine the additional data with the detections of video stream. This is not possible with the above approach unless you block the main process.
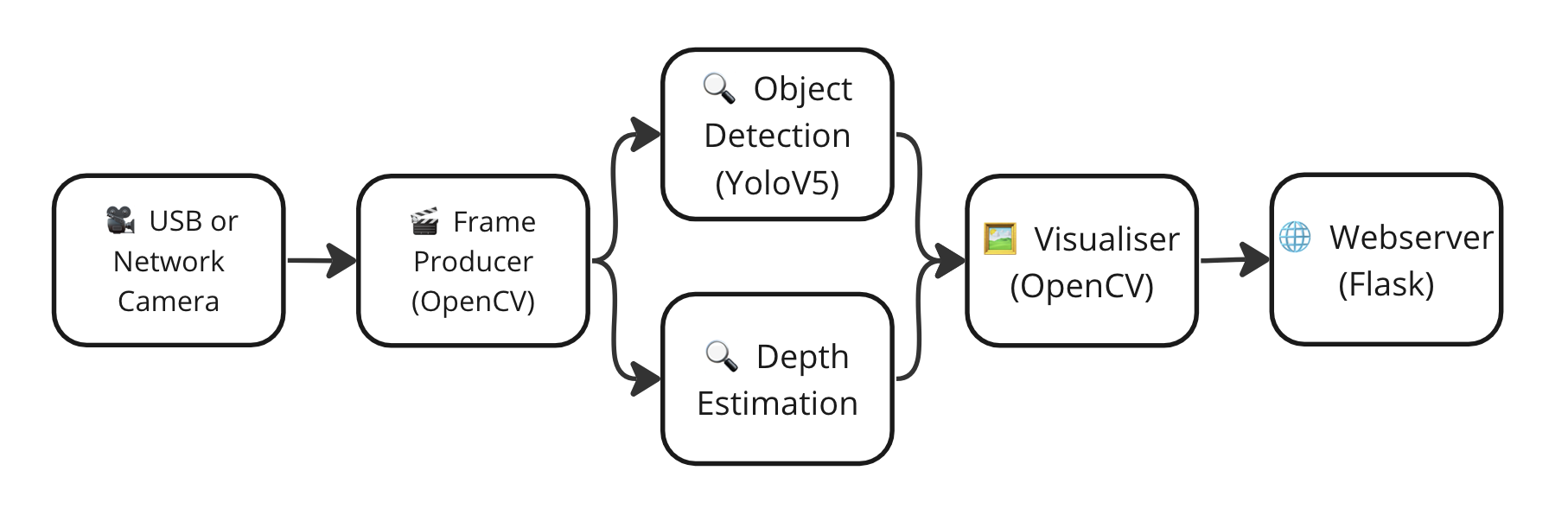
-
If you have mutliple models that you want to chain them together as a pipeline, combined with some python code in between. This is not possible with the above approach unless you block the main process. This can be models running in parallel or sequentially.
Parallel Example:
Sequential example:

- The image being rendered on the flask application is not really a video stream, its just a series of images. This is not a problem if you are just displaying the video stream, but if you want to do something more advanced like streaming the video to a remote media server to be able to store the results, then you’ll need to do some additional work.
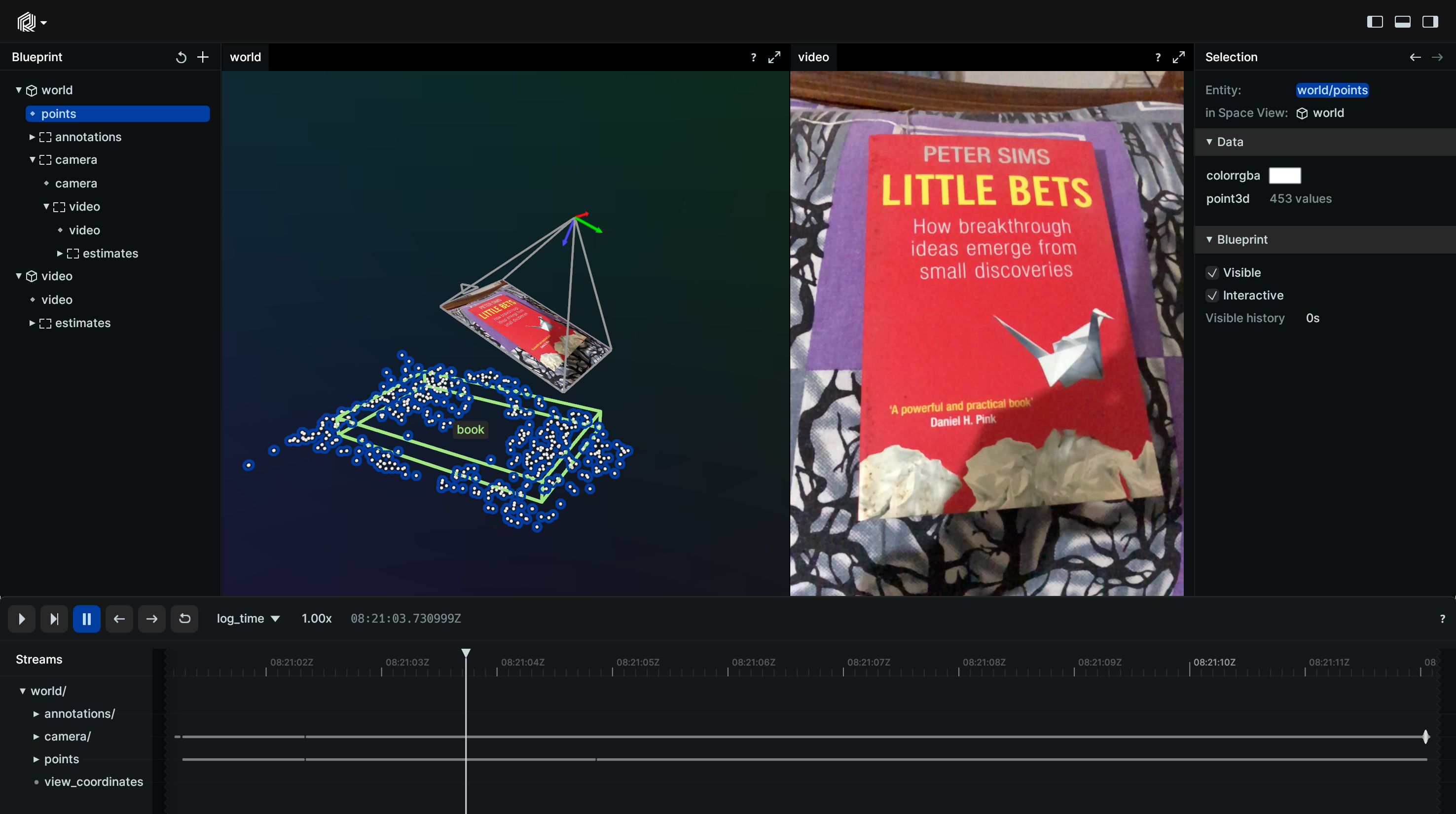
- If you want to visualise the vide stream along with the metadata generated by the video analysis pipeline in a dashboard with capabilities such as zooming, turning on or off different layers of metadata, going back and forth in the video.
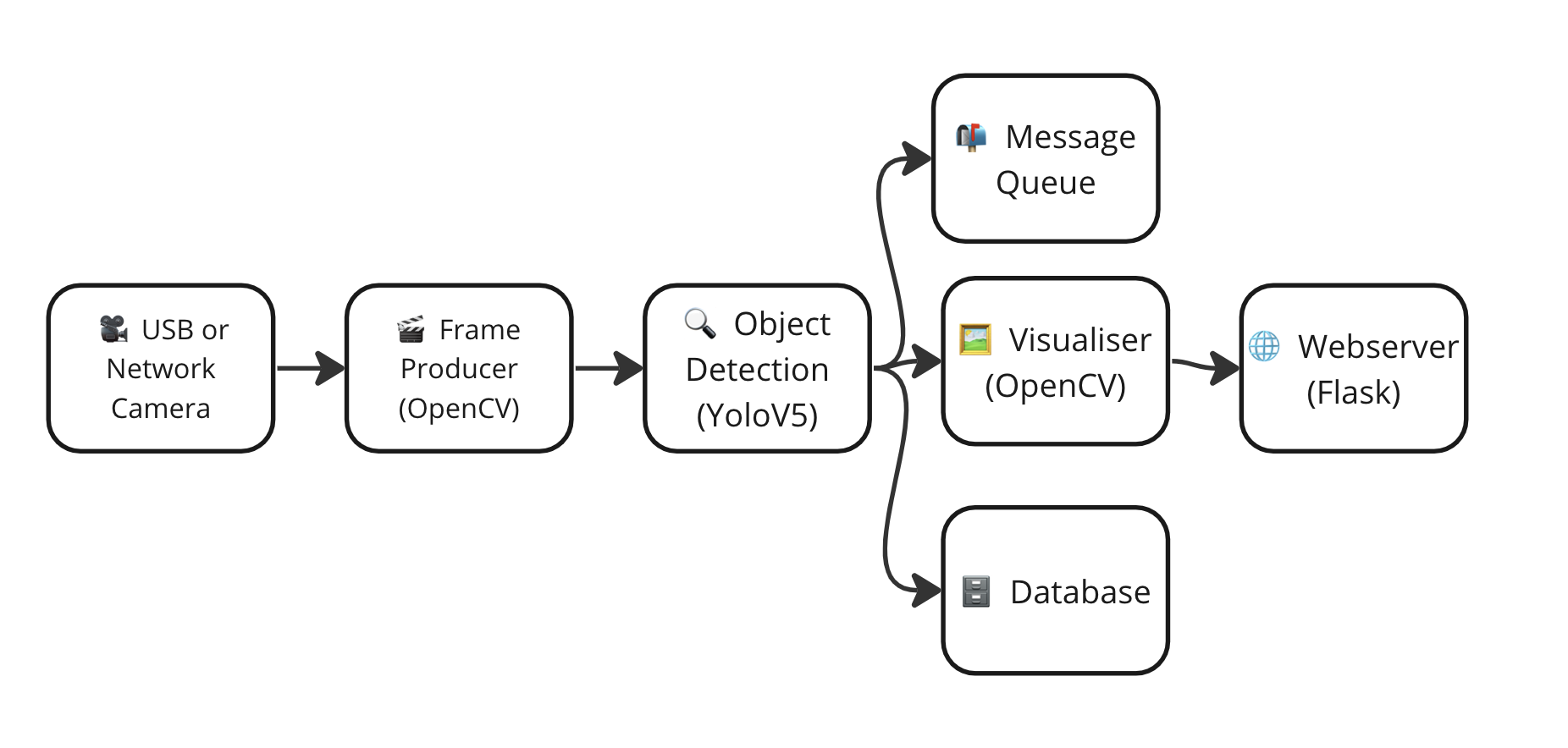
- This pipeline produces a video output only, what if you want to stream the model results to a database or a message queue? This is not possible with the above approach unless you block the main process.
- Image decoding, preprocessing and post processing happens using the CPU instead of GPU meaning there will be inefficiencies with copying data from CPU to GPU and data back to CPU also not utilising the GPU capabilities regarding the video streams to the to the fullest especially if you are running inference in parallel on different models.
Criteria for success:
In order to build a better solution, we need to define some criteria that we want to meet. Here are some of the criteria that we want to meet:
- Python based solution: we want to be able to use python to build our solution, we know we can use other higher performance languages like C++ or Rust, but we want to be able to use python as much as possible and only use other languages when absolutely necessary.
- Performance: being able to utilise the hardware resources efficiently and produce the most efficient solution possible (Stay nearly live)
- Modularity: being able to build a pipeline of different components that can be chained together to build a more complex system.
- Flexibility: being able to handle different types of data and different types of models
Existing Solutions
There are already existing alternatives to OpenCV and Flask that can be used to build a more robust system. However majority of these systems require huge upfront investment in learning also not all of them are pytho based, or event if they have python bindings its really hard to learn and debug some of these systems. If you know any more alternatives please let me know and I’ll add them to the list.
Most famous alternative is probabbly DeepStream SDK from Nvidia. This is a great solution if you are using Nvidia hardware and you are willing to invest in learning the system. Paul Bridger has a great series of blog posts explaining how to use Python, DeepStream and Pytorch to construct a video analysis pipeline and utilze the GPU to the fulles.
Whats coming up next?
Ok, I think we have enough background to start building a better solution. In the next post we’ll start building a better solution and we’ll go through the challenges that we face and how to overcome them. Stay tuned!